
안녕하세요. CloudOps팀 조수빈입니다.
클라우드 환경은 온프레미스 환경과 달리, 눈에 보이지 않는 데이터 센터와 네트워크 인프라 위에서 운영되기 때문에 직접적인 관리가 어렵습니다. 그만큼 보안 위협이나 장애 발생 시 대응 체계가 더욱 중요합니다.
이러한 이유로, 클라우드를 사용하는 고객 분들께서 보안과 장애 대응에 대한 우려와 궁금증을 가지고 계실 것이라 생각하여, 이번 글에서 CloudOps 팀이 어떻게 보안 관리와 장애 대응을 하고 있는 지에 대해 공유하고자 합니다.
개발부터 운영에 이르기까지 어떻게 보안을 강화하고, 어떻게 장애에 대응하는 지에 대해 알아보겠습니다.
Genians는 여러 클라우드 제공 업체를 통해 SaaS 서비스를 고객에게 제공하고 있습니다. 아래 그림은 NAC 서비스 구성도 입니다.
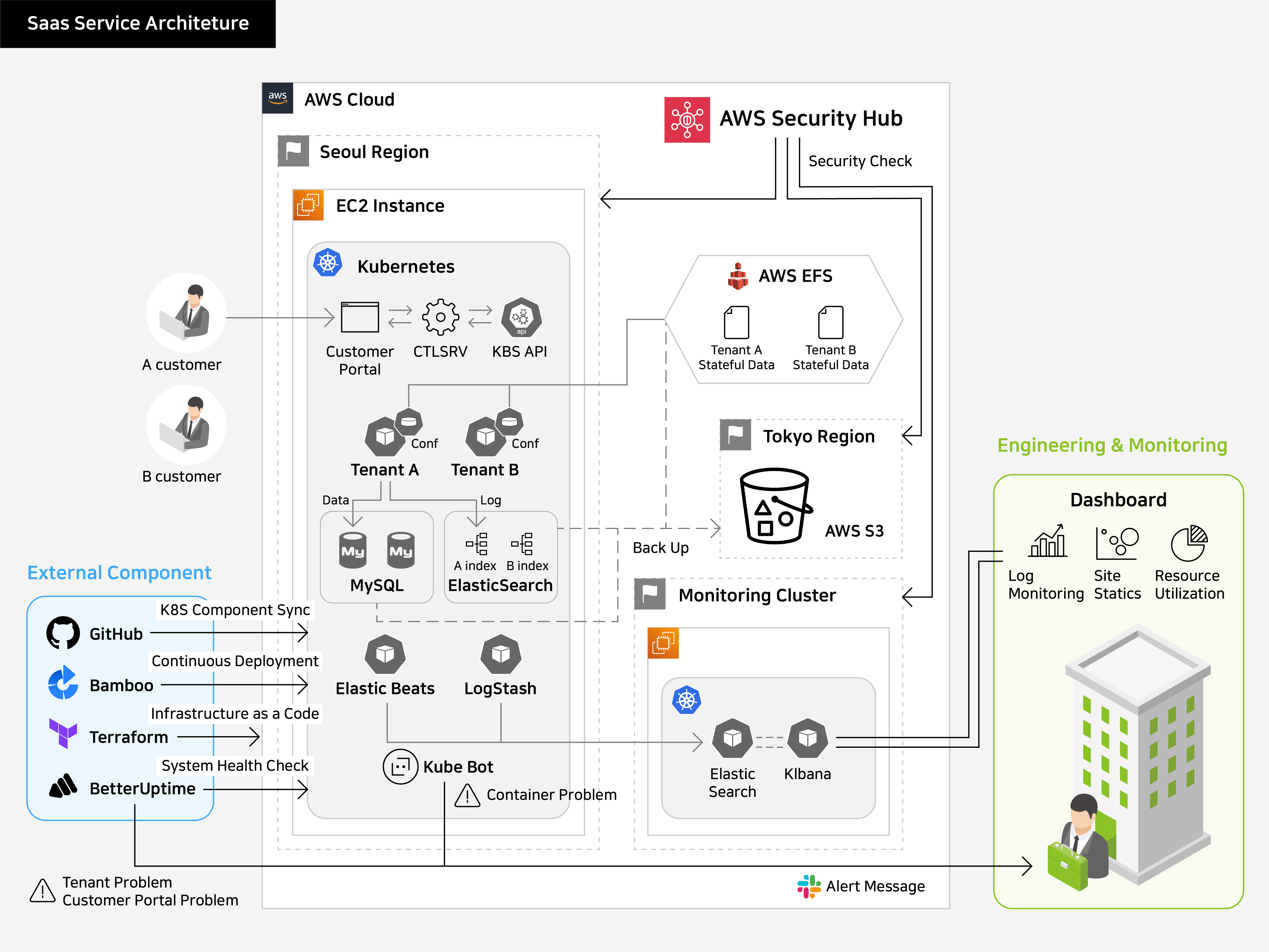
NAC 서비스 자체에 대한 설명은 생략하고, 이 글의 주제인 CloudOps 팀은 보안을 위해 어떠한 방법과 도구를 사용하는지 소개해 드리겠습니다.
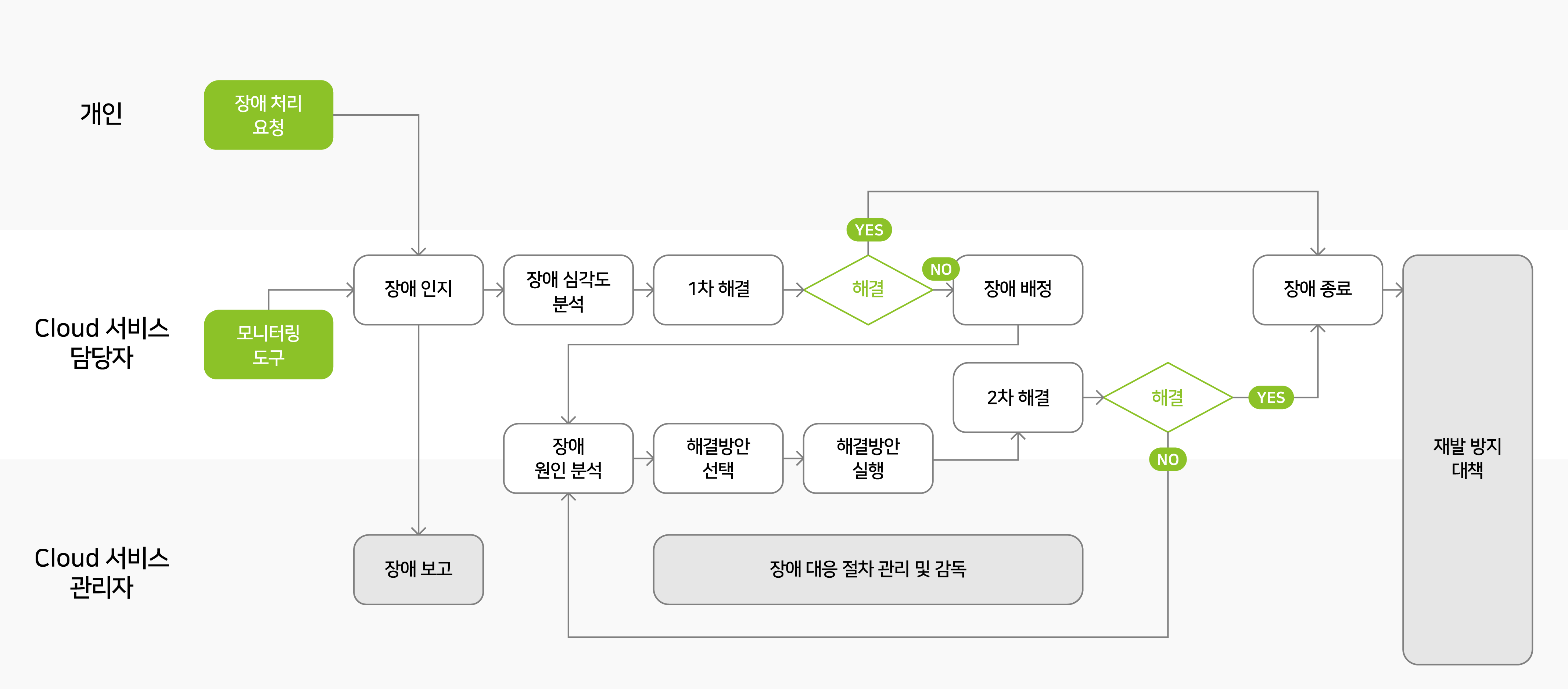
이제, 보안 뿐만 아니라 서비스의 신속한 복구와 대응을 위해 마련된 CloudOps 팀의 장애 대응 방안을 설명 드리겠습니다.
아래와 같은 장애 처리 프로세스로 신속하게 처리하고 있습니다.
그럼 장애를 어떻게 모니터링하고 있고, 장애 대비를 어떻게 하고 있는 지를 소개해 드리겠습니다.
1. 모니터링
-
실시간 대시보드: 실시간으로 시스템 상태를 확인할 수 있는 대시보드를 통해 주요 지표와 서비스 가용성을 모니터링 합니다.
-
서비스 가용성 모니터링: 서비스의 가용성을 지속적으로 확인하여 장애 발생 시 신속하게 대응할 수 있습니다. 주요 서비스의 상태 변화에 민감하게 반응하도록 구성되어 있습니다.
-
Kubebot 알림: Kubebot을 사용하여 클러스터 상태와 관련된 알림을 자동으로 받습니다. 이를 통해 장애 징후를 조기에 발견하고 신속히 대응할 수 있습니다.
-
자체 스크립트: 특정 상황에 맞춘 자체 스크립트를 통해 자동화된 모니터링 및 알림 기능을 보완하고, 특정 장애 유형에 대한 맞춤형 대응이 가능합니다.
2. DR(Disaster Recovery) 구성
-
AWS 리전 장애 대비: AWS 리전 장애에 대비해 다른 리전에 백업본을 저장하는 DR(재해 복구) 계획을 구성하고 있습니다. 이를 통해 특정 리전에 문제가 발생하더라도 서비스가 중단되지 않고 다른 리전을 통해 빠르게 복구가 가능합니다.
-
Terraform 사용: 인프라 자동화를 위해 Terraform을 사용하여 백업 구성 및 복구 절차를 코드화합니다. 이를 통해 재해 발생 시 빠르고 일관된 복구가 가능하며, 필요 시 자동으로 다른 리전으로 전환할 수 있습니다.
-
재해 복구 훈련: 1년마다 자체적으로 재해 복구 테스트를 수행하고 있습니다.
이러한 테스트를 통해 실제 재해 상황에서도 서비스 복구가 원활하게 이루어지는지 점검하며, 절차 상의 문제점을 사전에 발견하여 개선할 수 있습니다.
또한, 훈련을 통해 팀의 대응 능력을 강화하여 예기치 못한 장애에도 신속히 대응할 수 있도록 준비하고 있습니다.
이와 같은 체계적인 모니터링과 DR 구성을 통해 CloudOps 팀은 장애 발생 시 빠르고 신뢰성 있게 대응하며, 서비스의 가용성을 보장하고자 노력하고 있습니다.
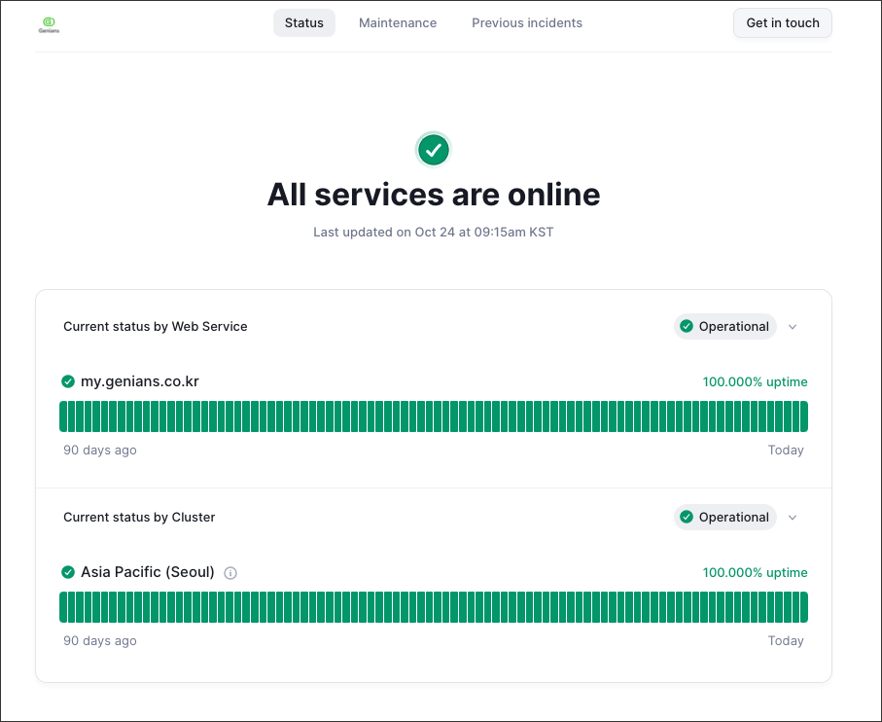
CloudOps 팀은 장애 발생 시 신속하게 대응할 뿐만 아니라, 사용자들에게도 장애 정보를 투명하게 제공하고 있습니다.
클라우드를 이용하는 모든 고객은 실시간으로 서비스 상태를 확인할 수 있습니다.
또한 서비스 상태 페이지에서 "Previous Incidents" 메뉴를 통해 지난 90일 이내에 발생한 장애 및 그 사유를 확인할 수 있도록 게시하고 있습니다.
CloudOps 팀은 개발에서 운영까지 철저한 보안 관리와 체계적인 장애 대응을 통해 안정적인 서비스를 제공하는 데 최선을 다하고 있습니다.
고객의 입장에서 생각하며, 지속적인 개선과 혁신을 통해 더욱 향상된 서비스를 제공하는 것을 목표로 성장하고자 합니다.
글을 읽어주셔서 감사드리며, 직접 체험을 원하시는 고객께서는 Genian Cloud NAC를 방문하시어 자유롭게 체험하실 수 있습니다.
글쓴이.조수빈
지니언스 기술연구소에서 Cloud 운영 개발을 담당하고 있습니다.







